


脳画像データの機械学習による統合失調症に特化した判別手法を開発
プレスリリース
東京大学
日本医療研究開発機構
発表者
小池 進介(東京大学大学院総合文化研究科 附属進化認知科学研究センター 准教授/東京大学国際高等研究所ニューロインテリジェンス国際研究機構(WPI-IRCN)連携研究者)
発表のポイント
- 複数の脳構造画像データセットを高精度に統合する技術を新たに用いることにより、統合失調症の判別に寄与し、新規のデータにおいても汎用性の高い機械学習器(注1)を開発することに成功しました。
- 疾患群と健常群を判別する機械学習を、より早期の疾患群及び発達障害群にも応用できることが確認できました。
- 実際の臨床現場で必要とされる、鑑別診断や治療予測などのマーカーとしての応用が期待されます。
発表概要
東京大学大学院総合文化研究科附属進化認知科学研究センター・小池進介准教授、東京大学医学部附属病院精神神経科・笠井清登教授、東京大学医学部附属病院放射線科・阿部修教授、浜松医科大学医学部精神医学講座・山末英典教授(前東京大学医学部附属病院精神神経科准教授)らの研究グループは、慢性期統合失調症、及び健常対照の方から計測された複数の磁気共鳴画像(MRI)の脳構造画像データセットを用いて機械学習を行い、70%以上を判別可能な機械学習器を開発し、統合失調症早期群、発達障害群における予測可能性を検討しました。
これまでの精神疾患脳画像を用いた機械学習は、主に同一施設・プロトコルにより計測されてきたデータを使用し、新規のデータにおける応用が検討されることはほとんどありませんでした。しかし、臨床現場では新規の対象において、精神病リスクまたその発症について早期発見及び鑑別診断が求められています。
今回開発した機械学習器は、統合失調症の異なる臨床病期(精神病ハイリスク、初回エピソード精神病)及び発達障害群の脳画像データを当てはめると、統合失調症、健常対照どちらかに判別されました。また、慢性統合失調症として判別される確率は、精神病ハイリスクより初回エピソード精神病の方が高く、発達障害群の80%以上が健常群として判別されました。そのため、本研究による機械学習器は、臨床現場で必要とされる、鑑別診断や治療予測などのマーカーとしての応用が期待されます。
発表内容
研究の背景・先行研究における問題点
精神疾患の診断は、現在でも精神科医による問診が主な判断基準となっており、血液や画像などを用いた客観的な診断補助が求められています。機械学習は近年より一般的になった分類手法で、これまで統合失調症や発達障害でわかっていた脳構造画像の特徴を用いて、診断補助となりうる可能性を秘めていました。しかし、これまでの精神疾患脳画像を用いた機械学習研究では、限られた疾患群と健常群のデータを用いた研究がほとんどで、多施設・プロトコルデータにおいて機械学習器の応用はこれからの課題でした。また、開発された機械学習器を異なる臨床病期のデータ、たとえば発症リスクや発症初期の方に当てはめ、その性能を評価することは行われてきませんでした。特に発症前後では、診断を確定することが難しい場合が多く、治療方針の確定が困難なケースがあります。臨床現場で判断が難しい場合に、客観的な診断補助の機会があれば、より適切な治療に結び付けられる可能性があります。
そこで、本研究グループでは磁気共鳴画像(MRI)の脳構造画像データを用いて、1)慢性期統合失調症、健常対照の2つをわける機械学習器を開発し、2)この機械学習器にはどういった脳構造特徴が重要かを明らかにすることにしました。そして、3)機械学習器判別と重症度の相関を検討し、4)この機械学習器開発には使用していない独立した異なる統合失調症臨床病期(注2)(精神病ハイリスク、初回エピソード精神病)及び発達障害の脳構造画像を当てはめ、この機械学習器が疾患群と健常群を判別できるかを検討しました。
研究内容
慢性期統合失調症83名、健常対照113名の研究参加者から計測された脳構造画像(テストデータセット(注3))をCAT12という解析ソフトウェアを用いて、全脳の灰白質を抽出し、計554,992の脳構造特徴変数を求めました。PythonのSkLearnライブラリにあるサポートベクターマシーン(SVM)(注4)を用いて機械学習器を構築し、異なるプロトコルで撮られたデータセットを用いて機械学習器の性能を評価しました。
機械学習器は判別率のほか、各疾患群で症状が重症であるほど、判別がより疾患寄りになるかの関係も評価しました。また、独立サンプルとして、精神病ハイリスク27名(数年間で統合失調症発症リスクが20%程度あるといわれている群)、初回エピソード精神病24名(精神病症状[幻覚、妄想など]を発症してまもない群)及び発達障害64名の研究参加者から計測された脳構造画像(独立確認データセット(注5))を同様の方法で脳構造特徴変数を求め、開発された機械学習器に当てはめました。
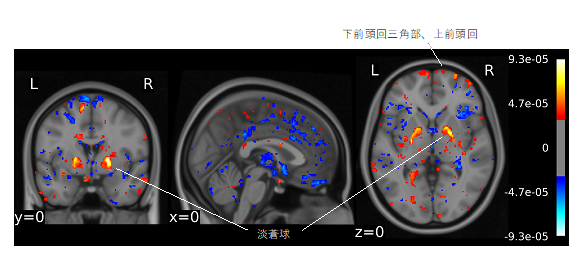
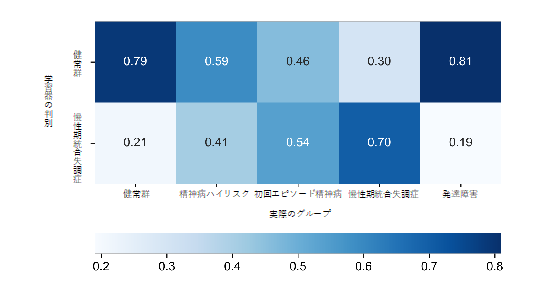
その結果、機械学習器の精度はテストデータセットで75%でした。さらに、独立確認データセットでも76%と精度を維持しました。両側淡蒼球と下前頭回三角部は、慢性期統合失調症の分類に重要な特徴量を示しました(図1)。統合失調症臨床病期群は、発達障害群と比較して慢性期統合失調症として分類されました(慢性期統合失調症への分類率:精神病ハイリスク、41%;初回エピソード精神病、54%;慢性期統合失調症群、70%;発達障害群、19%;健常者群、21%,図2)。
社会的意義・今後の予定
本研究は、多施設、異なるMRI機種や計測パラメータで得られた脳画像を用いて、慢性期統合失調症、健常対照の2つの群を分ける機械学習器を開発しました。それを独立した異なる統合失調症臨床病期のデータに当てはめ、その性能を検証した世界初の研究になります。機械学習器の予測情報は、神経画像技術を臨床鑑別診断に適用し、疾患の発症を早期に予測するのに役立つ可能性があります。これまでの精神疾患脳画像を用いた機械学習は、同一施設・プロトコルにより計測されたデータを使用し、機械学習器を構築するものでした。しかし、臨床現場では新規の対象において、精神病リスクまたその発症について早期発見及び鑑別診断が求められています。本研究で得られた機械学習器の予測情報は、鑑別診断や治療予測などのマーカーとしての応用が期待されます。
また、この機械学習器は、これまで統合失調症の脳病態と考えられてきた淡蒼球や下前頭回三角部などの重要性を改めて指摘しました。これまでの機械学習研究では、既存の脳画像研究成果と整合性が取れず、その信頼性が疑問視されている部分がありました。今回の機械学習器では、既存の脳画像研究成果との整合性も取れており、今後、機械学習解析を利用したさらなる病態解明も期待されます。
今後は、多施設共同研究データで得られた脳画像で多疾患について、どのような手法を用いればよいのか、といった検証を重ね、統合失調症及び発達障害の病態解明、また一般的な医療機関で計測されるMRIデータへの応用を目指していきたいと考えています。
研究支援
本研究は、日本医療研究開発機構(AMED)戦略的国際脳科学研究推進プログラム(国際脳: JP21dm0307001, JP21dm0307004)、革新的技術による脳機能ネットワークの全容解明プロジェクト(革新脳; JP21dm0207069)、日本学術振興会科学研究費補助金(JP19H03579, JP20KK0193, JP21H02851, JP21H05171, JP21H05174)、科学技術振興機構ムーンショット目標2(JPMJMS2021)の助成により支援されました。また、東京大学人間行動科学研究拠点(CiSHuB)、ニューロインテリジェンス国際研究機構(WPI-IRCN)、昭和大学文部科学省共同利用・共同研究拠点(発達障害研究拠点)の支援を受けました。
発表雑誌
- 雑誌名
- Schizophrenia Bulletin(オンライン版:2022年3月30日)
- 論文タイトル
- “Application of a machine learning algorithm for structural brain images in chronic schizophrenia to earlier clinical stages of psychosis and autism spectrum disorder: A multi-protocol imaging dataset study”
- 著者
- Yinghan Zhu, Hironori Nakatani, Walid Yassin, Norihide Maikusa, Naohiro Okada, Akira Kunimatsu, Osamu Abe, Hitoshi Kuwabara, Hidenori Yamasue, Kiyoto Kasai, Kazuo Okanoya, Shinsuke Koike
- DOI
- 10.1093/schbul/sbac030
用語解説
- (注1)機械学習器
- データから直接情報の規則性や固有構造を見出し、将来の出力を予測できるアルゴリズムです。
- (注2)統合失調症臨床病期
- ほかの疾病と同じく、統合失調症も早期支援・早期治療が提唱されています。そのため、統合失調症をもつ方(もしくは、発症リスクのある方)が病気のどの段階にいるのかを把握することが重要です。本研究では、統合失調症臨床病期のうち、ハイリスク状態、初回エピソード、慢性期の3病期を対象に検討を行いました。
- (注3)テストデータセット
- 通常、機械学習器を開発する際、データセットをトレーニングデータセットとテストデータセットに分割します。トレーニングデータセットを用いて機械学習器を開発し、テストデータセットにより機械学習器の精度を評価します。
- (注4)サポートベクターマシーン(SVM)
- 教示あり機械学習手法のひとつで、与えられた変数を最大限用いて、異なる群を最も分離できるように超平面を作成します。
- (注5)独立確認データセット
- 機械学習器の開発に使われていない他施設・プロトコルのデータセット。機械学習器の開発に用いたトレーニングデータセットとの類似性が低いため、テストデータセットよりも開発された機械学習器の汎用性を確認できます。
お問い合わせ先
研究に関すること
東京大学大学院総合文化研究科 附属進化認知科学研究センター
准教授 小池 進介(こいけ しんすけ)
Tel:03-5454-4327
E-mail:skoike-tky"AT"umin.ac.jp
AMED事業に関すること
日本医療研究開発機構(AMED)
疾患基礎研究事業部 疾患基礎研究課
戦略的国際脳科学研究推進プログラム
〒100-0004 東京都千代田区大手町1-7-1 読売新聞ビル
Tel:03-6870-2286 Fax: 03-6870-2243
E-mail:brain-i”AT”amed.go.jp
※E-mailは上記アドレス“AT”の部分を@に変えてください。
掲載日 令和4年4月8日
最終更新日 令和4年4月8日