


脳内における価値判断:抽象化思考を生み出すための鍵―柔軟な新世代人工知能開発への期待―
プレスリリース
国立研究開発法人科学技術振興機構(JST)
国立研究開発法人日本医療研究開発機構(AMED)
本研究成果のポイント
- 抽象化思考とは、多くの情報の中から本質的な情報を抜き出して組織することです。
- 本研究では、人間が未知の新しい規則を学習する時にどのように抽象化思考をしているのかを検証し、その脳活動をfMRIで測定しました。
- その結果、研究参加者の抽象化思考を用いる能力は、時間とともに向上しました。
- 特に、抽象化思考で問題を解決する際には、価値判断に関わる脳領域が優先的に使われていました。
- さらに、デコーディッドニューロフィードバック(DecNef)技術を用いて、抽象化された情報に対応する脳活動に人工的に価値を付加することで、抽象化思考の使用を促進させることに成功しました。
- 今回の成果は高次な脳機能に関する新たな知見を提供するものであり、新たな学習戦略やリハビリテーション戦略の考案、さらには新世代のAIの開発にもつながるものです。
概要
株式会社国際電気通信基礎技術研究所(ATR)のAurelio Cortese、山本明日翔、川人光男、アルバータ大学のMaryam Hashemzadeh、ロンドン大学(UCL)のPradyumna Sepulveda、Benedetto De Martinoは、価値判断に関わる脳領域で抽象化思考が行われていることを実証しました。さらに、金銭的価値を期待した時の脳活動と、抽象化思考には因果関係があることを明らかにしました。また、デコーディッドニューロフィードバック(DecNef)技術[1]を用いて、抽象化された情報に対応する脳活動に人工的に価値を付加することで、抽象化思考の使用を促進させることに成功しました。
抽象化思考は、複雑な問題を単純化する最も効率的な方法です。ディープラーニングの分野で最も影響力のある研究者の一人である、Yoshua Bengioが示唆した(ⅰ,ⅱ)ように、抽象化思考を行う能力は、新世代の柔軟な人工知能モデルを開発するための鍵となる可能性を秘めており、人工知能の新たな発展につながると期待されます。
背景
これまで、脳が視覚などの感覚情報からどのようにして抽象化思考を作り出すのかを明らかにした研究はありませんでした。さらに、新しい未知の問題を解決する際に、脳自体がどうやって抽象化思考を自然に学んでいるかも不明でした。これらの仕組みが解明されれば、抽象化思考というヒトの脳の重要な機能の根幹に迫る発見となるだけでなく、人工知能の新たな発展にも大きく貢献することが期待されています。今回の研究では、通常、脳が金銭的価値を期待して選択を決定する際に使用すると考えられている脳領域の表現が、脳の抽象化思考を生成する能力の基礎になっている可能性があることを初めて明らかにしました。
研究内容
方法
実験では、33名の研究参加者に、このパックマン(図1A)はどちらの果物が好きなのか、それはどんな規則に基づいているかという連合学習課題を行ってもらいました。このパックマンは3種類の視覚的要因から構成されています(図1B f1色:赤か緑、f2線:縦縞か横縞、f3口の向き:右か左)。実験はブロックに分けて行い、各ブロックでは、ランダムに決められた2つの視覚的要因だけが規則を学習する上で意味があり、3つ目の視覚的要因は無関係となるように設定しました。この設定は研究参加者には知らされず、早く学習すればするほど、より大きい金銭報酬が得られることだけを伝えています。この課題の実施には,利用可能な3つの視覚的要因を全て使って判断する「時間がかかる」手法と、意味のある2つの視覚的要因のみで判断する「抽象化思考」を使用する「早くできる」手法の2つの手法のいずれかに従って解くことができます。また、各課題の最後にタスクをうまくこなせたかどうかという確信度の度合いを尋ねました(1(自信がない)~10(自信がある)の数値を用いて回答)。これらの問題を解く間、fMRI[2]で研究参加者の脳活動を記録しました。
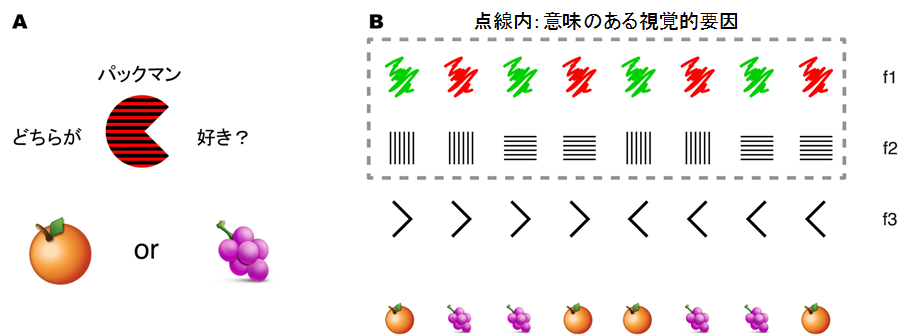
研究参加者は視覚的要因と果物の関連規則を学習する。
図1B:パックマンを構成する3つの視覚的要因と果物の組み合わせの一例。
研究参加者は色、模様、口の向きと果物の組み合わせを学習する。
実際には、2つの視覚的要因からのみでパックマンの好みを予測でき、もう1つの視覚的要因は無関係。
点線内は、意味のある2つの視覚的要因を示している。
行動の強化学習モデル化
研究参加者がどのような手法を用いてタスク問題を解決したかを理解するために、報酬だけを手がかりに教師無しで、試行錯誤から学習が可能な強化学習[3]モデルをコンピュータ上で設計・実装し、比較しました。まず、研究参加者がどのようにして正しい規則(パックマンはどちらの果物が好きか)を学習したかを明らかにするために、「特徴モデル」と「抽象化思考モデル」という2つの単純なモデルを用いて、あるブロックで研究参加者がどのモデルを使う可能性が高いかを判断しました(図2A)。「特徴モデル」は、すべての視覚的要因を利用する手法です。「抽象化思考モデル」は、関連する2つの視覚的要因だけで構成された抽象化思考を利用し、関連しない3つ目の視覚的要因は無視する手法です。これらのモデル化を検証した結果、課題をたくさん解けば解くほど、「抽象化思考モデル」を使う傾向が強くなることがわかりました(図2B)。
さらに重要なのは、金銭的価値への期待が抽象化思考の選択へ導くことがわかったことです。また、研究参加者の確信度(メタ認知[4]能力の重要な要素)は、抽象化思考の能力と正の相関を示しました(図2C)。
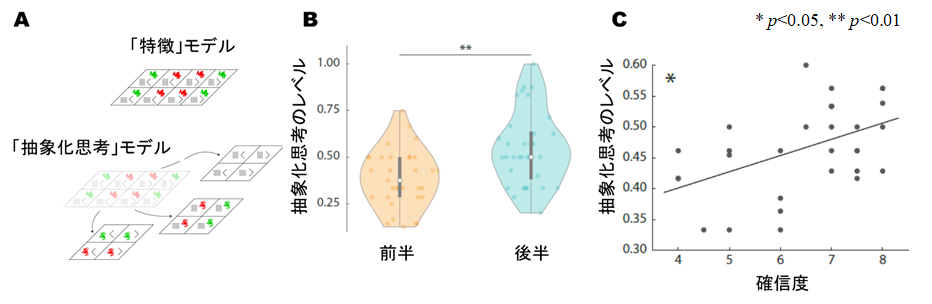
図2B 課題数と強化学習モデルの関連
課題の前半(Early)から後半(Late)にかけて、抽象化思考のレベルが上がっている
図2C 確信度と抽象化能力の関連
確信度と抽象化思考の能力は正の相関を示す
腹内側前頭前野(vmPFC)の中枢機能について
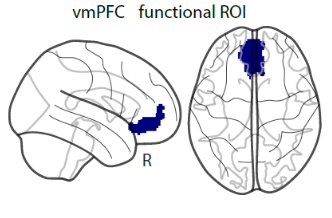
報酬を期待する意思決定に大きく関与している脳の領域に、腹内側前頭前野(ventromedial prefrontal cortex, vmPFC)[5]という領域があります。今回、私たちは、この領域が新しい価値信号を構築する際に、視覚野と機能的につながっていることを初めて示しました(図3A)。さらに、モデリングから推測されるように、研究参加者が抽象化思考を用いた時にも、vmPFCが優先的に使われることがわかりました(図3B)。これらの結果から、vmPFCは、視覚情報(この課題ではコンピュータの画像を使用したため)について価値信号を構築し、抽象化思考の過程でこの価値信号を使用することがわかりました。では、どのようにして価値信号が抽象化思考の生成に使われるのでしょうか?
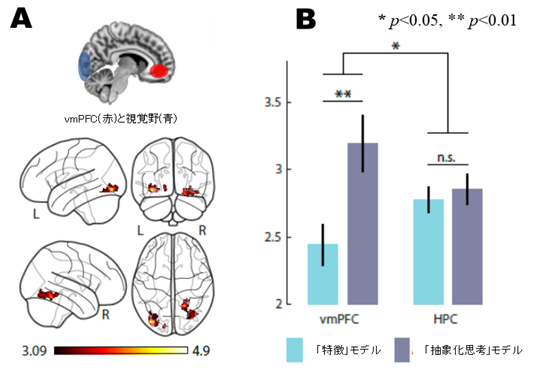
図3B vmPFCは抽象的な戦略を用いるときに活性化する(海馬(HPC)との比較)
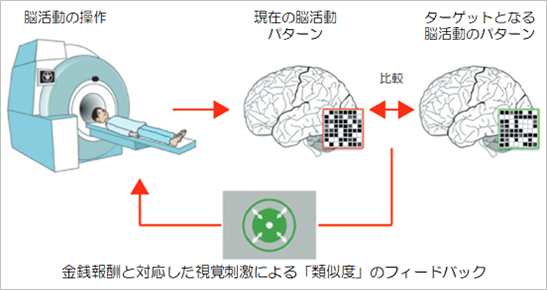
デコーディッドニューロフィードバック:脳活動に価値を付与することで抽象化思考を促進する
ここまでの結果から私たちの研究グループは、価値信号が、関連する視覚などの感覚情報の選択に使われているという仮説を立てました。もしこれが本当なら、ある視覚的要因を見ている時の脳活動に価値を加えれば、それに関連した抽象化思考が特に促進されることが期待できるはずです。この疑問を検証するために、デコーディッドニューロフィードバック(DecNef)を用いました。全研究参加者のうち22名の研究参加者を対象とした第2の実験では、DecNefを用いて、1つの視覚的要因(例えば赤)を見ている時の視覚野の脳活動に対し金銭報酬を与えることで、人工的に価値を付与しました。2日間のDecNefトレーニングを行い、その後、第1の実験と同じ課題をもう一度行い、新しい未知の規則を学習してもらいました。
今回は、DecNefで訓練された視覚的要因(例えば赤)画像がパックマンに含まれている場合には、「関連する」と見なされ、含まれない場合には「関連しない」と見なされました(図4)。
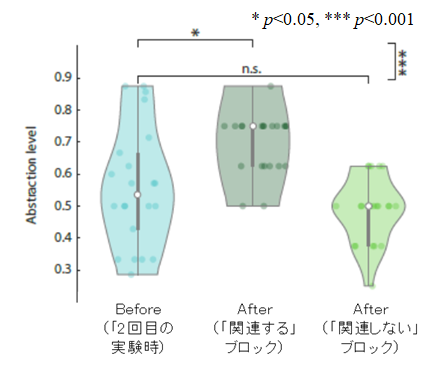
価値信号が抽象化思考を促進するという仮説通り、研究参加者は抽象化規則に「関連する」特徴が強化された場合にのみ、抽象化思考の使用が増加しました。この結果は、vmPFCとその視覚野との繋がりが、価値を期待する信号を通じて抽象化思考を構築し、それが感覚野のトップダウン制御として実行されていることを示す強力な証拠となります。
本研究の意義と今後の展望
科学的意義
これまで、脳が感覚情報から抽象化思考を構築する仕組みを科学的に実証した例はありませんでした。これまでの実験では、複雑な課題や刺激を用いていたため、個々の課題の特徴を追うことができなかったからです。私たちの手法では、脳がどのようにして各感覚情報を価値に統合し、効率的な学習行動を導くための抽象化思考を構築するのかを、学習のすべての段階で追跡することができました。DecNefをベースにした革新的な実験パラダイムを用いて、人間の脳では、金銭的価値が抽象化思考の使用と因果関係があることを示しました。
技術的な新規性
私たちのグループは、脳の活動をリアルタイムでモニターしたり、人々の自信を変えたり、色の認知を人工的に作り出したり、恐怖の記憶を取り除いたりすることを可能にする技術開発を、世界に先駆けて行ってきました。今回の研究は、これらの過去の取り組みに基づいていますが、いくつかの点で異なっています。それは、人間がさまざまな問題を解決するのにどのような戦略をとるかを調査するにあたり、まず新しい行動タスクと強化学習モデルの枠組みを使用した点、次にタスクパラメータの1つを脳内で人工的に変更する手段としてDecNefを使用したという点で大きく異なっています。このような方法はこれまで誰も行ったことがなく、今後の新たな研究の重要な出発点となると考えられます。
今後の展望
本研究では、人間が抽象化思考を用いて学習する際に、脳内の価値付けメカニズムを用いることの実証に成功しました。「価値判断に関わる意思決定の計算を行うvmPFCという脳領域が、どのような状況で、どのような理由でそれを行うのか」という、これまでの研究で行われてきた議論に重要な解決策を与えました。一方で、この領域は、情報の構造や新しい概念の学習にも深く関わっており、価値判断と抽象化思考が関連していることを明らかにしました。私たちの研究は、そのような2種類の異なる研究を統合するものであり、vmPFCの計算は関連する情報を選択し、抽象的・概念的な表現を構築するために金銭的価値が必要な場合に行われることを明らかにしました。この知見は、価値付け・抽象化思考・学習についての新しい考え方につながることを期待しています。
また、この結果は、脳科学と人工知能を融合した新しい研究に繋がるでしょう。特に、より優れた人工知能を開発するための研究に役立つと期待しています。また、本研究は、精神疾患の患者さんの新しい学習方法やリハビリテーション方法にも新たな知見をもたらすと考えられます。
倫理面での懸念に対する対応
新しい技術の使用と開発、実験デザイン、および脳の内部メカニズムの理解には、倫理的側面に最大限の注意を払う必要があります。特に神経科学やAIの分野では、新しい知識やアプリケーションが生まれ、未知の領域へと移行していくため、その傾向は顕著です。問題が複雑な場合に、人間が少量のサンプルから学習する仕組みを理解することは、それ自体は何の問題もないように思えますが、その結果が人間の知能レベルに達する新しいAIの開発につながるとなると心配になります。さらに、人間が潜在的にどのように学習しているかを理解することも重要なポイントになります。このようなプロトコルを開発することは、ある種の洗脳に似ていると考える人もいるでしょう。私たちは、これらの潜在的な問題を慎重に検討するとともに、倫理や生命倫理の専門家と連携し、倫理安全委員会で研究者を評価することで倫理的な問題に対処していきます。
論文著者名とタイトル
- 掲載誌
- eLife誌(英国時間 2021年08月3日8時00分公開)
- 著者名
- Aurelio Cortese, Asuka Yamamoto, Maryam Hashemzadeh, Pradyumna Sepulveda, Mitsuo Kawato, Benedetto De Martino:
- タイトル
- Value signals guide abstraction during learning. eLife.
- DOI
- 10.7554/eLife.68943
研究グループ
株式会社国際電気通信基礎技術研究所(ATR)
Aurelio Cortese※1、山本明日翔※2、川人光男※3
(※1UCLと併任、※2奈良先端科学技術大学院大学と併任、※3理研AIPと併任)
アルバータ大学
Maryam Hashemzadeh
ロンドン大学(UCL)
Pradyumna Sepulveda、Benedetto De Martino
研究支援
本研究は、日本医療研究開発機構(AMED)戦略的国際脳科学研究推進プログラムの「脳科学とAI技術に基づく精神神経疾患の診断と治療技術開発とその応用」課題 JP18dm0307008 (研究開発代表者 川人光男)の支援を受けています。一部は科学技術振興機構(JST) ERATO「池谷脳-AI 融合プロジェクト」(JPMJER1801)(研究総括 池谷裕二)の一環として行われたものです。またMaryam Hashemzadeh はチリ国立研究開発機構(ANID)・奨学金プログラムから、Benedetto De Martino 准教授は、Welcome Trust (グラント番号:# 102612/A/13/Z)からの支援も部分的に受けています。
補足説明
- [1]デコーディッドニューロフィードバック(Decoded Neurofeedback, DecNef)
- fMRI([2]を参照)と人工知能技術組み合わせ、対象とする脳領域に特定の活動パターンを誘導する方法です。著者らによる先行研究(Shibata et al., Science, 2011, Cortese et al. Nature Comms 2016)において、世界に先駆けて開発されました。
- [2]機能的磁気共鳴画像法(functional Magnetic Resonance Imaging, fMRI)
- 脳全体の血流量の変化を画像化する技術です。脳血流量は脳活動の度合いを反映しているため、この画像を解析することで、各脳部位の活動度合いを推定することができます。
- [3]強化学習(RL, Reinforcement Learning)
- 強化学習は、AI・ロボティクス・神経科学に大きな影響を与えている、経験から学習する強力なアルゴリズムの一つです。学習者である「エージェント」がある設定された環境の中で、環境から与えられる報酬が一番多くなるような行動を獲得するための機械学習法です。強化学習ではエージェントが環境と相互作用して行動を学習する様相を特徴付けます。エージェントは、自分の取った行動が良かったか悪かったかを、その行動で得られた報酬に基づいて「価値」として計算し、価値が高い行動を高い頻度で選ぶように学習します。経験を通して、エージェントは世界のある状態に関する信念(報酬に関わる)を獲得し、最も適切な行動を選べるように学びます。強化学習は試行錯誤によって学習する方法で、ヒトや動物の学習方法と類似すると考えられています。
- [4]メタ認知(Metacognition)
- メタ認知は自分自身の心的な能力や認知過程を監視する能力です。また、メタ認知は私たちのさまざまな行動決定、記憶、そして思考の現実性あるいは信頼度までも監視する機能でもあります。自己モニタリングも含まれます。視覚認知の確信度判定も、メタ認知の一種です。さらにメタ認知は意識と深く関係しています。
- [5]腹内側前頭前野(vmPFC)
- 腹内側前頭前野は脳の前方、前頭葉の中でも中心寄り(左脳と右脳の接する面)に位置している脳領域です。先行刺激・反応・結果といった行動の随伴性をモニターして、その行動の価値を更新する機能を持つとされており、経済的な価値判断にも大きく関わっていると考えられています。
引用文献
(ⅰ) Bengio, Yoshua. 2017. “The Consciousness Prior.” arXiv , http://arxiv.org/abs/1709.08568.
(ⅱ) Goyal, Anirudh, and Yoshua Bengio. 2020. “Inductive Biases for Deep Learning of Higher-Level Cognition.” arXiv. http://arxiv.org/abs/2011.15091.
お問い合わせ先
研究内容に関すること
株式会社国際電気通信基礎技術研究所(ATR)経営統括部 企画・広報チーム
〒619-0288 京都府相楽郡精華町光台2-2-2
Tel:0774-95-1176 Fax:0774-95-1178
E-mail:pr“AT”atr.jp
株式会社国際電気通信基礎技術研究所(ATR)
JST事業に関すること
国立研究開発法人科学技術振興機構 研究プロジェクト推進部 ICT/ライフイノベーショングループ
内田 信裕
〒102-0076 東京都千代田区五番町7 K’s五番町
Tel:03-3512-3528 Fax:03-3222-2068
E-mail:eratowww“AT”jst.go.jp
報道担当
国立研究開発法人科学技術振興機構 広報課
〒102-8666 東京都千代田区四番町5番地3
Tel:03-5214-8404 Fax:03-5214-8432
E-mail:jstkoho“AT”jst.go.jp
AMEDの事業に関すること
国立研究開発法人日本医療研究開発機構 疾患基礎研究事業部 疾患基礎研究課
戦略的国際脳科学研究推進プログラム
〒100-0004 東京都千代田区大手町1-7-1 読売新聞ビル22F
Tel:03-6870-2286 Fax:03-6870-2243
E-mail:brain-i“AT”amed.go.jp
※E-mailは上記アドレス“AT”の部分を@に変えてください。
掲載日 令和3年8月3日
最終更新日 令和3年8月3日