


膨大な文献データをつなぎ合わせて新たな関連性を導出する手法を開発―COVID-19関連薬の探索へ応用―
プレスリリース
東京大学
日本医療研究開発機構
発表のポイント
- 利用可能な文献アブストラクト(約2千万件)を解析し、様々な生体分子や生命現象間の関連性を導出、連結することにより新たな関連性を推定するシステムを開発しました。
- このコンピュータープログラムは、研究者が関連論文を読んでそれぞれの関連性をつなぎ合わせながら新規の関連性を推定する方法を模した手順で行うところに新規性があります。
- 今回はCOVID-19関連薬の推定に応用し検証を行いましたが、どのような生体分子、生命現象についての関連性の推定にも適用可能です(他の疾病関連薬の推定など)。
発表概要
深刻な感染症COVID-19の収束には特効薬が望まれますが、新薬の開発・実用化には時間が必要です。代替法として他の疾病に対する既存薬の転用も検討されていますが、莫大な化合物が対象となるため、まず先に論理的検討により候補を絞り込むことが効率的です。この目的のため、東京大学大学院農学生命科学研究科の村松知成特任准教授と田之倉優特任教授はCOVID-19の治療薬候補を特定するための新しく強力なツールを開発しました。これは生体内における各種反応、現象、物質などの相互関連性に基づきます。文献データベースPubMed#1)と生体内における各種反応、現象、物質を扱うKEGG#2)という2つの巨大なデータベースを用い、PubMedの要約フィールド(アブストラクト)を解析することにより、21,589,326件のPubMed IDと98,556件のKEGGコードを関連付け、それから各KEGGコード間の関連性を導き出し、それらを繋いでいくことにより新たな関連性を推測します。今回はこの方法によりCOVID-19関連薬の推定を行いましたが、このプログラムは他の感染症にも適用でき、将来新しい感染症が出現した場合にも迅速な薬剤候補特定に役立ちます。
発表内容
地球規模で猛威をふるう新型コロナウイルスに対し現在最も有効な手立てとしてはワクチン接種がありますが、ウイルスの変異などにより将来的には同じワクチンが有効であるとは考えられません。なぜかというと、ワクチンとはウイルスのタンパク質(感染症COVID-19に対してはその原因ウイルスSARS-CoV-2のスパイクタンパク質)あるいはその一部(もしくはそのmRNA)を用いて我々の体の中で、それらに対する抗体を作らせるものであり、ウイルスによる感染が続くことによりウイルスタンパク質に多くの変異が蓄積してきた場合、あるいは大きくタンパク質の構造を変化させる変異が出現した場合には、現在使われているワクチンから誘導された抗体がそれらに対処できなくなることが考えられるためです。また、ワクチンは基本的に予防的手段であり、感染者に対する根本的な治療薬の必要性は依然として存在しています。ところがCOVID-19に対しては、インフルエンザに対するタミフルのような強力な特効薬は現状では存在しません。新薬の開発と実用化には長い時間が必要なのでその代替法として他の疾病に対する既存薬の転用(ドラッグリポジショニング)が検討されてきています。これを効果的に行うためには実験によるスクリーニングに先立ち、インシリコスクリーニング等コンピューターを用いた絞り込みが有効であると考えられますが、これにも数量的な限度はあります。また、これらの前段階スクリーニングは、作用機序を想定して行い、仮に実際には効いたとしても想定された作用機序と異なるものは見過ごされることになります。
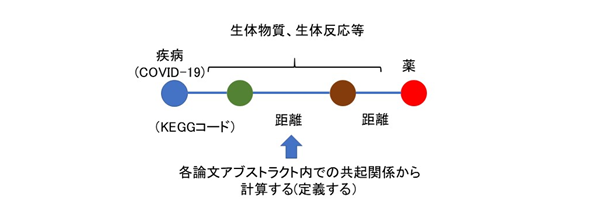
これに対し、今回、研究グループはPubMedという膨大な文献データベースの全体を用いてCOVID-19関連薬を探索・推定しました。これは、PubMedデータベースに含まれ、アブストラクト項目の存在する約2千万件のレコードについて、それらのアブストラクト部分での用語の共起に基づいて行ったものです。たとえば、”SARS-CoV-2”(新型コロナウイルス)と”ACE2”(アンジオテンシン変換酵素2)がアブストラクト内にともに存在する論文が頻繁に見られ、このことからこの2つの用語どうし、およびそれらが示す実体どうしの関連性が示されます。COVID-19、SARS-CoV-2など当該疾病に関係する用語と薬(既存薬)に関する用語の共起を調べ、それが存在するPubMedレコード(PubMed ID)の数から算出した「確からしさ」を評価するだけでなく、未だ報告のない関連薬との推定をも意図しています。
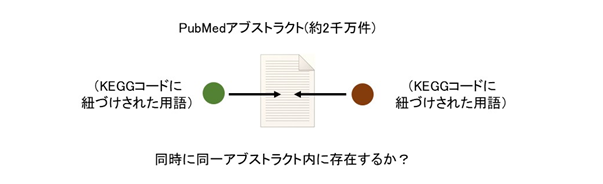
KEGG(Kyoto Encyclopedia of Genes and Genomes)という生体内における各種反応、現象、物質を扱うデータベースから抽出したすべての用語(疾病、薬以外も含む)間の関連性を、各PubMedアブストラクト項目での共起に基づき解析しました(図1)。各用語は抽出元となった各KEGGコードに紐づいているためKEGGコード間の関連性を得ることができます。
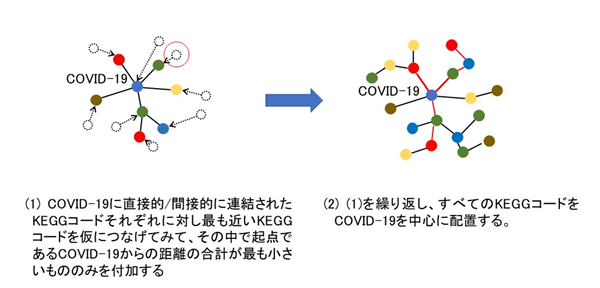
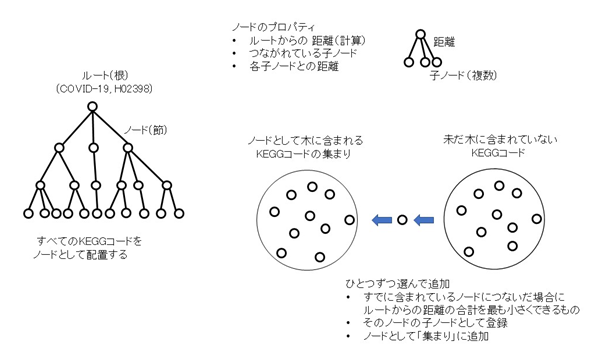
新たな関連性の推定については、次のように行います。新たな関連性の推定は三段論法的な考え方をします。すなわち、関連性の大きなものどうしをつないでいくのです(図2)。まず、KEGGコード間で関連性が強くなるほど小さく(近く)なるように距離(関数)を定義します。そして、COVID-19(KEGG:H02398)を起点にすべてのKEGGコードについて、それらの直接距離あるいはいくつかの他のKEGGコードを介した距離の中で最も近くなるように配置するのです。これは、概念的には次のように行います。COVID-19に直接的/間接的につながれた(連結された)KEGGコードそれぞれに対し最も近いKEGGコードを仮につなげてみて、その中で起点であるCOVID-19からの距離の合計が最も小さいもののみを付加することを繰り返していきます(図3)。実際には、この構造は木(tree)構造#3)と同値であり、すべてのKEGGコードをひとつずつ木構造のノードとして定義していくことになります。ノードとして定義されたどれかのKEGGコードにつないでみたときに最もCOVID-19からの距離が小さくなるKEGGコードを未だノードとして定義されていないKEGGコードの中から探し出し、新たにノードとします。そのときにそれをそれにつないだノードの子ノードとして登録します。それぞれのノードが持っているデータはCOVID-19からの距離、つながれている子ノードのリストとそれらとの距離だけでよく、新たに選定するノードのCOVID-19からの距離計算は、親ノードとの距離と親ノードのCOVID-19からの距離を加えることにより容易に求まります。作業としては、それぞれのKEGGコードを選んでどの親ノードにつなぐかを決定し、親ノードの子ノードデータとして追加する、ということになります。そして、候補薬のリスト作りでは、その中に現れた薬コード(Dコード)をそれに至る距離の合計が小さい順に拾っていきます(図4)。
この方法の検証は次のように行いました。COVID-19とPubMedアブストラクト内で直接共起の見られた薬について、その直接共起情報のみをすべて除いてコードをつないで行くことにより得られる間接的な距離と、直接見られた共起から計算される距離を比較します。近い距離のものからリストアップすると上位よりレムデシビル、ヒドロキシクロロキン、アビガン等を先頭に妥当と思われる順で関連薬が並び、また、それらの中では間接距離と直接距離の良い一致がみられることから、方法の有効性が確認されました。逆に、PubMedアブストラクト内での直接共起が見られないにもかかわらず、比較的近い距離で間接的につながる薬もあり、これらは新薬候補とすることができます。
今回開発したプログラムの特徴としては以下のものを上げることができます。
- COVID-19関連薬探索のみならず、他の任意の疾病に対する薬の探索・推定にも用いることができる。特に、将来、新たな感染症が出現した場合、初期段階では、その感染症では直接的な薬の報告がない状態となるが、その場合にも関連薬候補をリストアップすることができる。
- さらに、疾病-薬関係だけではなく、あらゆる生命現象間の関連性の抽出・推定にも用いることができる。
- 用いている距離の計算は用語どうしのPubMedアブストラクト内での共起に基づく。したがって、今後、この部分の改良を行うことによってさらに精度の高い予測を行えるようになる可能性がある。
- すべてのデータはPubMed IDに紐づけされており、容易に元論文を確認することができる。
- PubMedアブストラクトからの用語の抽出には一般的に自然言語処理で用いられるステマー(すべてを小文字化し、語幹のみを抽出するプログラム)を医学や生物学で多用される語尾(-ase, -ose, -ine, -sisなど)や大文字略語(DNA、SARSなど)に対応できるように改変して用い、文献マイニングとしての情報抽出精度の向上も図っている。
本研究は、国立研究開発法人日本医療研究開発機構(AMED)創薬等ライフサイエンス研究支援基盤事業 創薬等先端技術支援基盤プラットフォーム(BINDS)(課題番号JP20am0101068)の支援を受けて行われました。
発表雑誌
- 雑誌名
- Bioinformatics Advances(2021年7月22日、Advance article)
- 論文タイトル
- A novel method of literature mining to identify candidate COVID-19 drugs
- 著者
- Tomonari Muramatsu*, Masaru Tanokura*
- DOI番号
- 10.1093/bioadv/vbab013
- 論文URL
- https://academic.oup.com/bioinformaticsadvances/advance-article/doi/10.1093/bioadv/vbab013/6325500
参考URL
用語解説
- #1)PubMed(パブメド)
- アメリカ国立衛生研究所(NIH,National Institutes of Health)の運営する文献データベース。各論文には固有のID番号(数字)が割り当てられている。1966年以降の論文を扱い、32,944,707報の論文情報が含まれ、そのうち22,037,808報については要約フィールド(アブストラクト)が存在する(2021年8月25日現在)。
(National Library of Medicine) - #2)KEGG(京都ゲノム百科事典,Kyoto Encyclopedia of Genes and Genomes)
- 1995年京都大学科学研究所金久研究室で開発され、現在も更新が続けられている、遺伝子、タンパク質、代謝物の情報およびそれらに含まれる分子間の相互作用、生体内反応等の関係性を統合したデータベース。それぞれの項目(エントリー)には、カテゴリーごとに定められた1~2文字の英字と5桁の数字からなるコード番号(またはEC番号)が割りあてられている。
(KEGG:Kyoto Encyclopedia of Genes and Genomes) - #3)木構造(tree structure)
- 要素間の関係を定めるデータ構造の一つで、ある1つの要素を始点として閉回路が生成しないように要素をつないでいったもの。それぞれの要素をノード(節)とよぶ。それぞれのノードは他のいくつかのノードにつながっているが、ノードとノードのつながり(連結線)をエッジ(枝)とよぶ。始点となるノードはルート(根)とよぶ。あるノードに注目した場合にはそれにつながるノードについてはルートとの関係において方向性があり、エッジをつたってルートに到達することができるつながりで直接つながっているノード(1つだけ)を親ノード、それ以外を子ノード(0個以上)とよぶ。子ノードを持たない(子ノードが0個の)ノードをリーフ(葉)とよぶ。木構造とはいうが、この構造を図示する場合は、根を上に、葉を下に、倒立した形で表現する。
お問い合わせ先
研究内容に関する問い合わせ
東京大学 大学院農学生命科学研究科
特任准教授 村松 知成
Tel:03-5841-2279
E-mail:atmuramatsu“AT”g.ecc.u-tokyo.ac.jp
特任教授 田之倉 優
Tel:03-5841-5165
E-mail:amtanok“AT”mail.ecc.u-tokyo.ac.jp
AMED事業に関する問い合わせ
日本医療研究開発機構 創薬事業部 医薬品研究開発課
創薬等ライフサイエンス研究支援基盤事業(BINDS)
Tel:03-6870-2219
E-mail:20-DDLSG-16“AT”amed.go.jp
※E-mailは上記アドレス“AT”の部分を@に変えてください。
関連リンク
掲載日 令和3年9月10日
最終更新日 令和3年9月10日