


AMEDシンポジウム2017開催レポート:成果報告④ 大規模ゲノムコホートとデータシェアリング(2)
 成果報告④ 大規模ゲノムコホートとデータシェアリング
成果報告④ 大規模ゲノムコホートとデータシェアリング
山本 雅之氏(東北大学東北メディカル・メガバンク機構長)
スパコンを活用した複合バイオバンク

図3 統合データベースdbTMMの開発
※画像をクリックするとPDFファイルが表示されます
東北メディカル・メガバンク機構では、参加者の方々から、データの二次利用を可能にする非常に強いインフォームド・コンセントをいただいています。試料と情報の分譲審査は、外部委員を含む委員会により透明性を確保して実施されています。知的財産権は基本的に分譲先に渡しています。バンクの試料と情報は、国民の共有財産として今後、AIをはじめ多くの学術研究や産業振興に利活用してほしいと考えています。
バイオバンクではいただいた生体試料を匿名化して新しいIDを振ります。また、試料を分注・保管し、さらに、DNAを抽出したり、不死化リンパ球を作成したりしています。
複合バイオバンクの構築には、解析区画・分譲区画に分かれたスーパーコンピュータを活用しています。情報分譲区画につながる専用回線を設けているのですが、この設置には、現在神奈川県をはじめとして全国15カ所から申し込みを受けています。 複合バンクを支える一つの力が統合データベース「dbTMM」です。このデータベースには基本情報や生化学検査情報、ゲノム・オミックスの情報、質問票、生理学検査、MRI検査画像情報等がすべて収まっています。 複合バイオバンクでは解析センターも組織の中に含まれており、そこで解析されたゲノム・オミックス情報も一緒に分譲したり、統合・解析したりすることができます。
日本人のゲノム解析ツール「ジャポニカアレイ®」
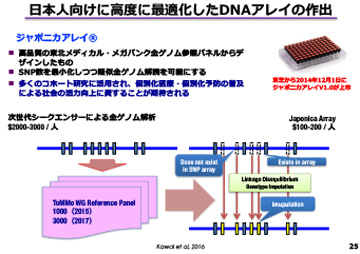
図4 日本人向けに高度に最適化したDNAアレイの作出
※画像をクリックするとPDFファイルが表示されます
病気発症に関連する遺伝子を同定・解明するゲノムコホート研究において、有用な情報を得るためには、家系情報を取り込むか、サンプル数を増やすかのいずれかが必要です。私たちは、家系情報を利用する方向に舵を切りました。そこで、最初に地域住民コホートで数千人の全ゲノム解析を行い、健常な日本人のゲノムの形を明らかにした「リファレンスパネル」を作りました。
さらに、このデータに基づき、簡単にしかも安価で日本人のゲノムを解析できる「ジャポニカアレイ®」というツールを作りました。本ツールを用いて、疾患と遺伝子変異を紐付けを広範囲に実施し、実際に候補が現れたら、三世代コホートでトリオ解析して、絞り込んで行こうと考えています。
ヒトゲノムは、30億(3×10の9乗)塩基対からできていますが、個人間では、3×10の6乗、0.1%ぐらいが違っていて、この違いが個性や多様性を作ると考えられています。1つの人種の中では、その10倍ぐらいの違いがあると言われています。これらの遺伝子の変異が、個人の体質や疾患への罹患率・感受性を決めており、希少変異ほど疾患への関連性が高いと考えられています。
世界で初めて単一施設・単一方式で解析
世界各地の単一遺伝子多型(SNP)を登録するデータベースは、さまざまなシーケンサーで、様々な方式により実施されたデータを寄せ集めたものですが、私たちのリファレンスパネルは、単一施設・単一方式で、高精度にゲノム解析したものであり、これは公開されたものとしてはおそらく世界で初めてです。
当機構で、2049人分のゲノムを解析したところ、2800万個の遺伝子変異が見つかりました。これを欧米人中心のデータベースと比較したところ、新たな変異が1800万個見つかりました。2800万個のうち約6割に、民族間の相違が見られたわけです。これらデータは全て、ポータルサイトやNBDCで公開しています。日本人特有の遺伝子変異に関するデータは、日本の疾患関連遺伝子やバイオマーカーの探索にとって強力な武器になるはずです。健常な日本人のリファレンスパネルは、病気の遺伝子の選別する際の対照配列として大変優れたもので、今後のクリニカルシークエンスの非常に強力な土台になります。
また、これからは万人に効果のある薬だけではなくある一群には効いて、ある一群には副作用が出るような薬も作ることが大切です。そのような層別化した創薬にはこのデータが必要です。
さらに、個別化予防のためには、病気へリスクを解明する必要があり、そのリスクの計測にこのリファレンスパネルが役立ちます。加えて、「ジャポニカアレイ®」は高品質な全ゲノム参照パネルからデザインされており、SNPsプローブ数を最小化してありますが、それでも疑似全ゲノム解読を効率よく行うことができます。これはシークエンサーを使った全ゲノム解析の10分の1のコストで済みます。
メタボロームプロテオームのデータも公開
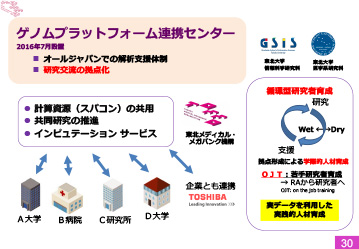
図5 ゲノムプラットフォーム連携センター
※画像をクリックするとPDFファイルが表示されます
AMEDのデータシェアリングのポリシーに基づき、私たちは1000人規模で、ゲノムが確定した人のメタボロームとプロテオームのデータ解析の結果をシェアリングしています。
「jMorp」と呼ばれるデータは利用可能な資料と情報を公開し、DNAや血漿、サンプルについては分譲申請をし、審査を経て利用できます。近い将来、2.3万人分のゲノム情報を含めたコホート情報を明らかにしようと思っています。
当機構内にゲノムプラットフォーム連携センターを作りました。これはオールジャパンで解析の支援体制、研究交流の拠点、スパコンによる共同研究推進の場として活用することが目的です。また循環型の研究者育成、OJTでのトレーニングも検討しています。
ゲノム医療研究の基盤構築を推進

私たちの事業は地域住民の協力の賜物であり、バイオバンクはメタボロームの専門家をはじめ、さまざまな職種の人に支えられています。さらに、若手医師が地域の被災病院を支え、地域医療を組み直す活動も展開してきました。
今後は、被災地の健康管理を続けながら、ゲノム医療研究の基盤構築も目指します。15万人のジャポニカアレイ解析、8000人程度の全ゲノム解析を予定しています。さらに個別化医療・個別化予防の先導モデルとして、パイロット研究にも取り組みたいと考えています。
最終更新日 平成29年10月17日