


アーカイブ インタビュー No.9「一人ひとりが"自分のゲノム情報を管理する時代"に向けて」

東京大学 大学院医学系研究科 衛生学分野 教授
病理学とバイオインフォマティクスとをバックグラウンドに、がんゲノムなどのデータ解析に携わり続けている石川先生。マイクロアレイから次世代シーケンサー(NGS)への分析手法の変遷を目にし、人工知能(AI)によるゲノムデータ解析という次世代の医療が手に届く現状をどのように見取っているか、お話を伺いました。
今、人工知能(AI)がゲノム研究にもたらす変化
― ヒトゲノム計画が終わる2000年頃に研究の道に入られましたね。バイオインフォマティクスを始める前、さかのぼるなら中学生、高校生時代から、バイオインフォマティクスの原点として数学とか、そういった分野がお好きだったのですか。
高校の時は余り意識しなかったですが、大学に入って物理や数学でいろいろな自然現象が数式で表現できる、それ自体が非常に面白いなと思ったことはあります。今はゲノミクスやバイオインフォマティクスをやっていますが、もともと私は医学部を出た後に病理学をやっていました。その後に東京大学 先端科学技術研究センター(以下、先端研)の油谷研究室で研究を始めました。そこで初めてゲノム解析がどういったことかを知って面白いと思いました。遺伝子・2万3000個の発現量の数字を一度に並べただけでは何がおこっているのか簡単には理解できないので、例えば次元を圧縮してデータを可視化するような技術は非常に面白いなと思いました。先端研にはそういう研究をしているグループがいたので勉強させてもらいました。
― そういった社会背景やそのころの研究テーマが今につながっているのですね。ご経歴の中、特に石川先生が取り組まれている人工知能(AI)の導入によって、ゲノム医療が今後どう変わるのかという観点からお話をお聞かせください。
はい。先端研で研究を始めた時には、もうヒトゲノムがデータベースにありました。このデータにいろいろなマイクロアレイなどのデータを照らし合わせて、がんの治療標的遺伝子を選ぶなどの研究に取り組んでいました。当時ヒトゲノム配列はほぼ完成していたのですが、個々の遺伝子などのエレメントがどういう機能を持っているかなどは、まだよくわかっていませんでした。特に遺伝子多型のような個体間のバリエーションについては全体像が全く未知でしたが。その後のHapMap計画による数百万におよぶSNPのカタログ化やコピー数多型地図の作成などを通して明らかになってきました。その後これらのデータを用いたGWAS等の解析で、数百もの疾患感受性と関連する多型が見つかりました。
ディープラーニングに代表されるAIが注目された1つのきっかけは2012年頃に画像認識において人の認識精度を上回るものが出てきたということです。ディープラーニングは画像や音声、言語処理などさまざまなところで利用されていますけれども、ゲノム情報にディープラーニングを直接使うことはまだまだ限定的です。画像や音声から「どういう特徴があるか」を抽出することには長けていますが、ゲノムはもともとベクトル化されているといいますか、きれいに並んで整理されているのでディープラーニングの強みが十分発揮できる状況を見つけるのが簡単でないのかもしれません。しかし、今後は推薦論文「Predicting the clinical impact of human mutation with deep neural networks」のように、ゲノム情報の解釈などにAIを使っていく研究が出てくるでしょう。
関連する話ですが、がんのクリニカルシーケンスの現場でも意義のよくわからない変異がたくさん出てきます。普通の人の配列とは違うけれども、本当にこの変異に病的意味があるのかどうかはわからない。このような問題も沢山の患者のデータを集めることによって病気と本当に関連があるのかどうかがわかってきます。それだけでなくほかの霊長類や哺乳動物の配列ではどうかとか、疾患によってたんぱくの構造がどう変わるかといったインフォメーションを入れると、この患者の変異が重要な変異かどうかということがある程度わかってきます。
― なるほど。そのための学習させておくデータというのは、変異とたんぱく質の立体構造の変化の関係というような?
あと、進化の保存性とか、そういうものを入れると、ある程度見えてくるように思います。
― そのようにAIの学習などを通して規則を学び、多くの症例でこれを繰り返すと、ゲノムの変異と疾患との関係が今までよりも高い確度でわかるようになるということですね。
最近は「人工知能で薬を選ぶ」といった活用も聞きます。それはまた別の種類のAIで例えば特定の遺伝子変異を持つがんの症例に効果のある治療薬に関して膨大な文献の中から適切な情報を選んでくるものです。文献の単語や文章の関係を解析する自然言語処理をベースにして重要で関連のある文献を選んでくる、例えばGoogleのページランクようようなものと似たようなものと考えられます。
― そうですね。AIと一口で言っても、アプリケーションも多々ありますし、処理の仕方や計算方法もいろいろあるということですね。
石川先生の推薦論文にある「ディープニューラルネットワーク」というのは、ディープラーニングの一種のやり方だと思うのですけれども、これは結構これからメジャーになってくる方法なのでしょうか。ニューラルネットワークは以前からありますから、これが何層もあるような?
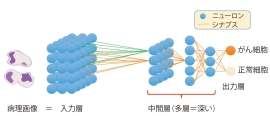
そうですね。先ほど少し触れましたがAIが今大成功している大きな一因は、ディープニューラルネットワークが画像解析などで力を発揮したことが大きいと思います。なぜうまくいくのか、どのような状況でうまくいくのかは、まだよくわかっていないところがありますが、個別の要素はは比較的単純で、行列みたいな数値を演算するステップだけでできています。(図1) 何層も並べると、多くの種類の関数が表現できることがわかってきて、いろいろな用途に使われています。
ただ、学習のためには多くのデータが要ります。例えば放射線の画像などはもともと病院で多くの患者に対して撮影していますので多くのデータが集まりますが、ゲノムデータとか、(特定の疾患の)病理画像データといったものはまだまだAIで分析できるほどの数を十分集めきれていないのが現状です。逆に少数のデータのみで、どうやってうまく学習するのかというのは技術的に面白いテーマになっています。また、データをきちんと学習のためにクリーニングするのも大変でそれも1つの大きな課題です。これらの課題がクリアされたなら、ある程度の難易度の問題に対する適切な判断はできるようになると思います。
― "判断"というのは?
医療の現場では様々な判断がありますが、例えば病理画像であれば「がんであるか、がんでないか」ということです。人工知能に慎重論を唱える人の意見としてよくあるのが「人工知能がなぜそういう判断をしたのかという判断根拠がよく分からない」というとことです。ただ最近では何か分類のような判別を下す時に、具体的にどの特徴を根拠にしているかというのを可視化して提示してくれる技術も出来てきています。あとは、医療機器などのレギュレーションが早い技術の進歩にどうやってついていくか、そこは多少ディスカッションが必要かなと思います。
― 慎重論ばかりで進まないと、いい技術もなかなか普及しないものです。適切な枠組みを決めた上で、どんどん社会で実装していけるといいのではないかと個人的には思うのです。
何かあったときの責任の所在、そこがしっかり議論できれば、それほど大きな問題にはならないのかなとは思います。それ(AIが導き出した答え)を参考にして、例えば今までどおりの医師が判断するとか。その点を曖昧にしておくと「機械がやった」ということになってしまいます。
ゲノム医療をコンシューマー・レベルにし、ゲノム情報を個人管理する時代へ

― 1人のゲノムを、1,000ドルで、わずか1週間で読む時代が到来していますね。
そうですね。1,000ドルぐらいですと、いわゆるコンシューマー(民間用、一般消費者向け)・レベルになります。ゲノムの解読に100万円かかるならば「病気になった時に医療機関で読んでもらおうか」となりますけれども、一般人が直接自分のデータを取り出すと、規模の経済で桁が違ってくる。またそこが広まると、ゲノムデータを解釈するためのいろいろな先端機器や人的サービスができたり、データ管理やセキュリティーのテクノロジーといったものも一体になって民間に広がるでしょう。民間のレベルにゲノム医療をおとしこむというのは、そういった意味で比較的大事なことなのではないかと私は思っているのです。
人材面もそうです。研究機関には今バイオインフォマティクスをやっている人材のキャリアアップが難しい状況もあります。しかし民間にそういうアクティビティーがあると就職先やその後のキャリアパスも増えてくる。こういう企業に行きたいからバイオインフォマティクスを勉強しようかみたいな若手も増えてくることもあると思ってます。ゲノムを扱うための、「この範囲までは自由にやって良い」というような様々なレギュレーションをある程度明確にすると、企業も参入しやすいと思うのです。
― バイオバンクの関連でもいろいろとリスクの議論などをされていて、インシデンタルファインディングス(偶発的所見)*1)をどうするかとか。例えば親子がゲノム解析して結果が返ってきた、突き合わせてみると、見る人が見れば親子関係がないということがわかってしまう可能性があるというところまでインフォームド・コンセント(IC)に書かなければいけないのかとか、どこまでインフォームするのかという問題。バイオバンクの場合に、サンプルを提供してくれた皆さんは"医療の発展のために"と思って提供してくれるわけでしょうけれども、厳密に言うと、プロジェクトが変わると同意を取り直さなければいけないのではないかとか、いろいろと手続論的なところもあると思います。私は結構包括的な同意でいいのではないかということは思っているのですけれども。そういった面で、確かに社会的に決めなければいけないことはありますね。
確かに自分のゲノムやその情報が何に使われるかというのを患者個人が把握するのは難しいと思いますね。今のシステムでは、医療機関などで患者が自分のDNAを研究試料として提供した後、しばらくは医療機関で管理をしてますが、医療機関を移す時にはオプトアウトで行われることもあり患者が気付かないことも十分あります。データベースとして公開されると後は誰がどのような目的で使うかはほとんどの場合直接患者には伝えられません。結局、患者側からは、自分のゲノム情報がどのような経緯で今どこにあって、どう使われているのか、なかなかトレースしにくいと思います。
いろいろな考え方はあると思うのですけれども、例えば患者個人が自分のゲノム情報をブロックチェーンような技術で暗号化してビットコインのように情報の流れをトレースすることで、自分のゲノム情報を管理する。患者自身も時には利益を得ることもありつつ、基本的にご本人の同意に基づき情報が集まってくるという仕組みもできるます。そういう意味も含めてゲノム情報を個人の管理するレベルにおとしこむいうのは課題はある一方で良い面が沢山あると思っています。
― ブロックチェーンの技術を使って、ちゃんとトレースできるようにするというのはいい考えだと思います。それでゲノム情報もちゃんと集まってくるのであれば、新しい可能性が出てくるということなるのですか。
個人が自分の意志や責任で研究機関や企業に提供したりしなかったりという判断がないと、不正使用や情報漏洩などの倫理的な事故が起こったときに大きな問題に発展する可能性があるとも考えられます。
― 1,000ドルゲノムのように(サービスの)低価格化によって、ゲノム情報を何かの段階で読んでおいて、それを個人に紐づけられると。それで、オーダーメード医療が適切に受けられるようになる。その辺も含めたゲノム医療の将来像、未来の社会を描く場合もあると思うのですが、石川先生はどう考えていますか。
それに近い印象を持っています。最初はいろいろなアカデミアなどの官学が主導するというのは重要だと思うのですが、そのままだと下がらない解析・人的コストや関連する人材の不足といった問題が表面化します。人材というのはバイオインフォマティシャンもそうですし、遺伝情報を適切に解説する人も含まれると思います。それが民間のドメインが扱うようになれば最初は多少混乱があるかもしれませんが、ゲノム情を解析しますとか、結果を正しく説明するコンテンツを作りますとか、そういう企業が出てきて競争が起こりまた関連知識を持つ人材の教育や就職も活性化して全体がボトムアップされていくように思います。
その際には先ほどのブロックチェーンもそうですけれども、セキュリティーの技術はやはり重要だと思います。例えば単純な暗号化だけでなく、先方にゲノム情報を復元できない形で伝えて特定の解析をして結果だけもらうとか、そういったことを可能にする技術も開発されつつあると聞いています。個人が自分でゲノム情報を持って個人で判断して使っていく状況であれば、広告のしかたによっては希少疾患の患者団体が直接的にゲノム自分達の情報を企業や医療機関に提供するようなアクティビティーも出てくる可能性があります。
高度医療だけでなくゲノム情報利活用の裾野を広げる
あと、今までゲノム情報の利活用は医薬品開発が主対象になっていましたが、例えば「保健機能食品」*2)など食品の疾患予防効果の検証などにも使えるのではないでしょうか。「機能性表示食品」は、 "健康への働き"についての製品の臨床試験や成分の文献調査などを消費者庁に提出すれば、企業の責任においてその働きを表示できると聞いています。
そういったところまでゲノム研究の領域を広げ、バイオバンクなどをうまく利活用して調査・分析・介入して市販前・市販後の予防効果を見てみる。それも医薬品開発での治験のような費用がかからないシステムづくりも今後面白い試みだと思います。
― 科学的なエビデンスに基づく予防のための健康食品を作っていくというのも大事ですね。特定保健用食品(トクホ)ですと、国の審査を受けるため、効果や安全性のための臨床試験などに億単位の費用がかかるという話です。機能性表示食品ですと、既存の論文など科学的根拠書類を提出すれば開発企業の責任で表示できますから、少しは規制緩和になっているかとは思いますが、バイオバンクの利活用という側面で、より一層の規制緩和が必要ではないでしょうか。
単純な疾患コホートの場合は、個人のゲノム情報とカップルして食品の予防効果を見るということは簡単にはできないと思うのですが、例えば東北メディカル・メガバンクのように発症前の個人をプロスペクティブにフォローしているバンクであれば、このような使い方も考えられると思います。
― 関連して、どんな運動をしたら予防になるかといったこと。一部保健学などで研究されているかもしれませんが、事例の蓄積ではなくて、今後はよりエビデンスベーストな研究となってゆくのではないでしょうか。
特定のゲノムの特徴を持つ個人が、あるタイミングで、特定の食品を食べると予防効果が高くなるとか、このようなものはまさにプレシジョン・メディシンではないでしょうか。予防医療に食品をうまく介入させるためには、あまり調査コストがかかって最終的な高価格として反映されないよう国がバイオバンク利活用に際して補助するということは十分あってよいかと考えます。
― バイオバンクのデータは民間も使える仕組みになっていますが、もっと広くアナウンスして使いやすくするということでしょうか。
今の対象は医薬品とか高度医療が主ターゲットとされているように感じますが、健康増進やいわゆる健康食品などに裾野を広げてアナウンスできれば良いと思います。
近年GWASなどで多くの疾患関連SNPが明らかにされ、遺伝子タイピングにより健康に関連する情報を提供するということが可能になりました。こうした行為を医療機関を介さずに行うことで個人の混乱を生じさせるという可能がある一方で、このようなサービスを通して個々人がヘルスケアに関する情報を入手して、運動をしたり食品や生活習慣を変えることにつながることが考えられます。たとえSNPによって強い生物学的効果はなくても、生活変容というインパクトは非常に大きいと考えられ、そういう意味で民間のゲノム医療への参入のアクティビティーに非常に期待しているところはあります。
(取材日:2018年9月25日、聞き手:一般社団法人知識流動システム研究所 監事 隅蔵 康一)
用語解説
- *1)インシデンタルファインディングス(偶発的所見)
- ヒトゲノム・遺伝子解析研究の過程において当初は想定していなかった提供者および血縁者の生命に重大な影響を与える所見のこと。
参考:文部科学省・厚生労働省・経済産業省「ヒトゲノム・遺伝子解析研究に関する倫理指針」(平成13年3月29日、平成29年2月28日一部改正) - *2)保健機能食品
- 現在、健康への働きを表示できる保健機能食品には、「特定保健用食品(トクホ)」、「栄養機能食品」「機能性表示食品」の3種類があります。
「トクホ」には厳しい認定基準があり、国が食品ごとに効果や安全性を審査しています。「栄養機能食品」は、既に科学的な根拠が確認されたビタミンやミネラルなどの国が定めた栄養成分を基準量含んでいる食品であれば、特に届け出なくても表示できます。
そして、「機能性表示食品」は、「健康に効果がある」と企業の責任で表示できる食品です。これまで機能性を表示できる保健機能食品は「特定保健用食品(トクホ)」と「栄養機能食品」に限られていましたが、2015年4月に機能性表示食品制度がスタートしました。消費者庁に必要な書類("健康への働き"については製品の臨床試験や成分の文献調査などによって、"安全性"については動物・人に対する実験結果や既存の学術論文の調査など)を提出すれば審査はなく、国の基準値なども設定されていないので、企業の責任において健康への働きを表示できるのが大きな違いです。
なお、この3つの保健機能食品は「食品」に分類されるものであり、予防や治療を目的とした有効成分の効果と安全性が国に認められている「医薬品」や、育毛剤や入浴剤などの「医薬部外品」とは異なります。機能性表示食品は、疾病の診断、治療、予防を目的にしたものではありません。(参考資料:日本医師会ホームページ「健康の森」気になるコトバ「機能性表示食品」)
推薦論文
- タイトル
- Predicting the clinical impact of human mutation with deep neural networks
- 著者名
- Laksshman Sundaram, Hong Gao, Samskruthi Reddy Padigepati, Jeremy F. McRae, Yanjun Li, Jack A. Kosmicki, Nondas Fritzilas, Jörg Hakenberg, Anindita Dutta, John Shon, Jinbo Xu, Serafim Batzoglou, Xiaolin Li & Kyle Kai-How Farh
- 雑誌名
- Nature Genetics
- 号、発行年
- 50, pages1161–1170(2018)
研究者経歴
2000年に東京大学 医学部 卒業。2004年に東京大学より医学博士号取得。2004年より東京大学先端科学技術研究センター ゲノムサイエンス部門 特任助手。2007年より東京大学 大学院医学系研究科 人体病理学・病理診断学 助教、のち准教授。2013年より東京医科歯科大学 難治疾患研究所 ゲノム病理学分野 教授。2018年より現職。AMED「オーダーメイド医療の実現プログラム」のプログラムオフィサー(PO)を務める。専門分野は、がんの病理学、ゲノミクス、バイオインフォマティクス。
関連リンク
掲載日 令和元年5月7日
最終更新日 令和2年3月30日